With the advent of large language models(LLMs) enhanced by the chain-of-thought(CoT) methodology, visual reasoning problem is usually decomposed into manageable sub-tasks and tackled sequentially with various external tools. However, such a paradigm faces the challenge of the potential "determining hallucinations" in decision-making due to insufficient visual information and the limitation of low-level perception tools that fail to provide abstract summaries necessary for comprehensive reasoning. We argue that converging visual context acquisition and logical reasoning is pivotal for tackling visual reasoning tasks. This paper delves into the realm of multimodal CoT to solve intricate visual reasoning tasks with multimodal large language models(MLLMs) and their cognitive capability. To this end, we propose an innovative multimodal CoT framework, termed Cantor, characterized by a perception-decision architecture. Cantor first acts as a decision generator and integrates visual inputs to analyze the image and problem, ensuring a closer alignment with the actual context. Furthermore, Cantor leverages the advanced cognitive functions of MLLMs to perform as multifaceted experts for deriving higher-level information, enhancing the CoT generation process. Our extensive experiments demonstrate the efficacy of the proposed framework, showing significant improvements in multimodal CoT performance across two complex visual reasoning datasets, without necessitating fine-tuning or ground-truth rationales.
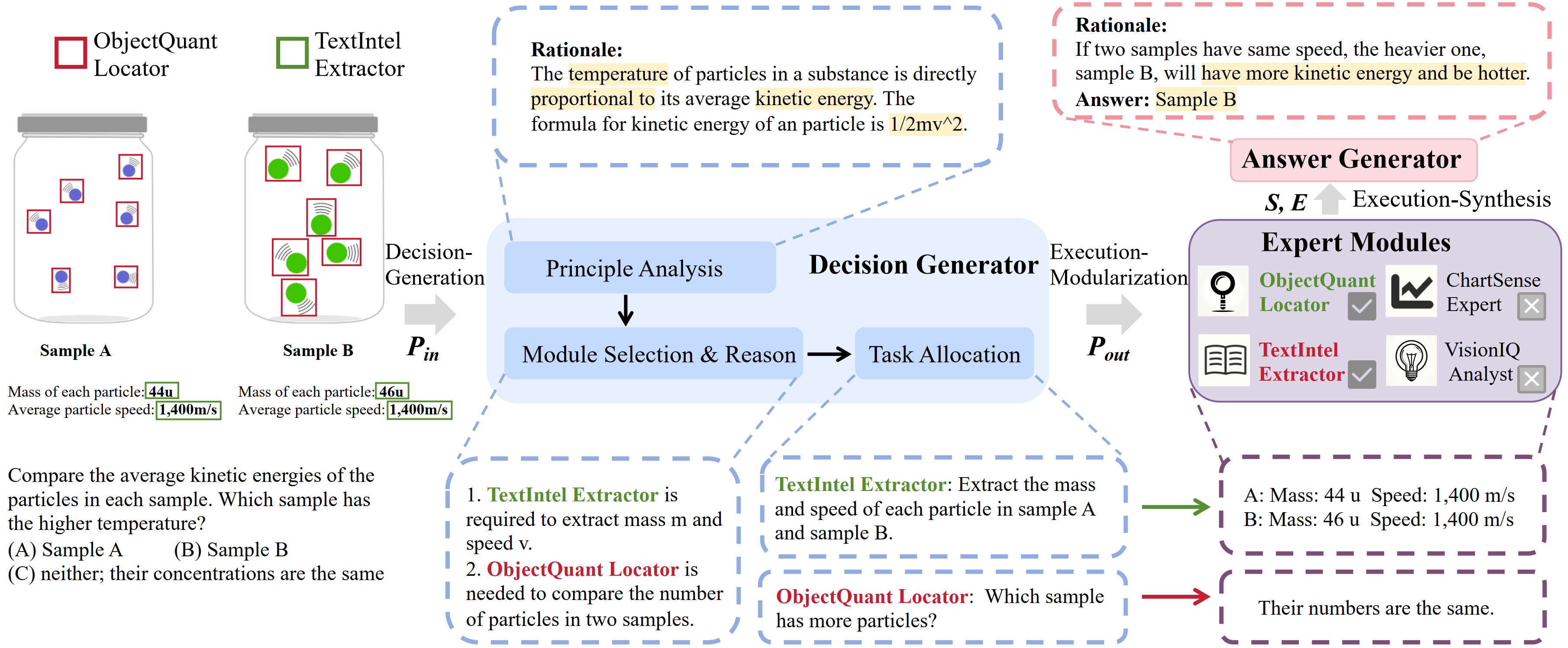
We propose an inspiring multimodal CoT framework named Cantor, which features a perceptual decision architecture that effectively integrates visual context and logical reasoning to solve visual reasoning tasks. Cantor consists of two stages: Decision-Generation and Execution:
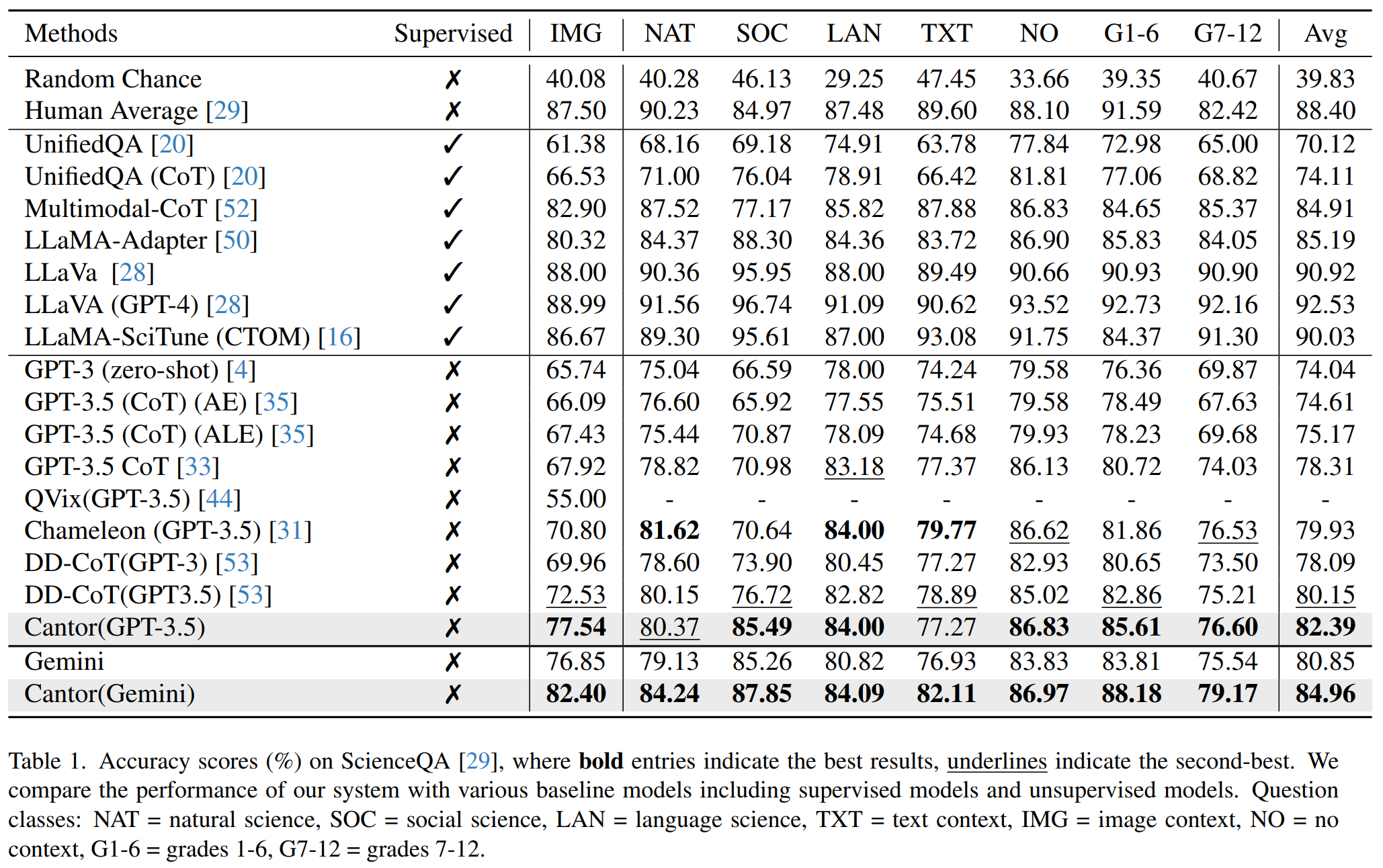
Tab. 1 shows the results of existing baselines compared to our method Cantor on ScienceQA. Using GPT-3.5 as the base LLM to decision and answer, Cantor achieves an accuracy of 82.39%, which is an improvement of 4.08% over the chain-of-thought (CoT) prompted GPT-3.5. Furthermore, with Gemini as the decision generator and answer generator, Cantor reaches an accuracy of 84.96%, significantly surpassing all training-free methods, and even outperforming fine-tuned methods like UnifiedQA (CoT) and MM-CoT.
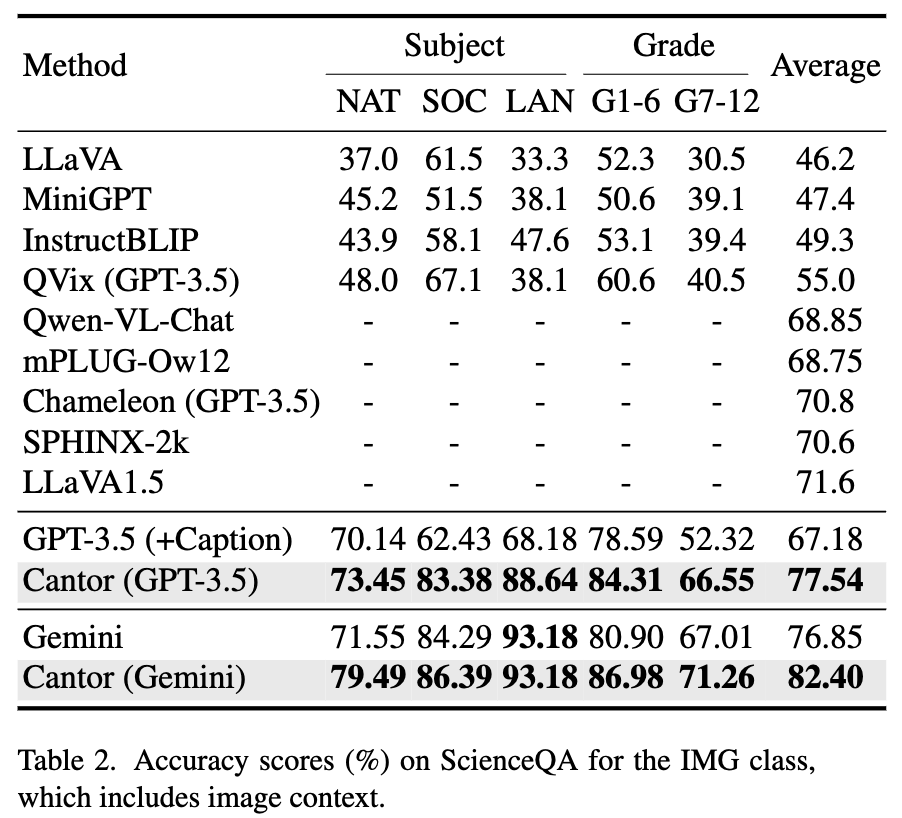
Particularly noteworthy is that Cantor advances in the multimodal domain. As shown in Tab. 2, we further present the accuracy of various methods on ScienceQA for the IMG class, which includes image context. It can be seen that Cantor based on GPT-3.5 significantly surpasses the baseline in various problems, and even surpasses well-known MLLMs such as SPHINX and LLaVA-1.5.
 MathVista:
MathVista: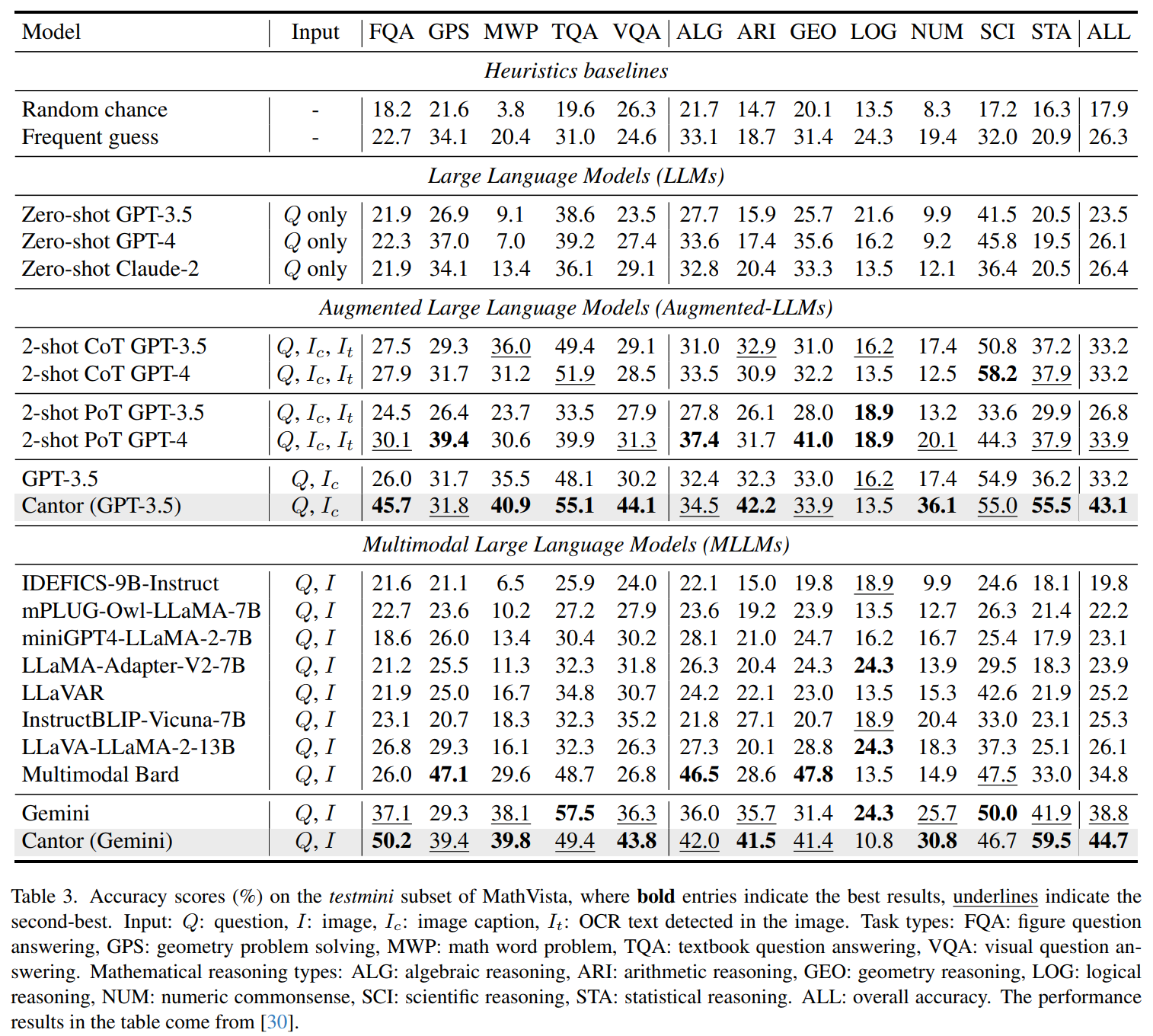
MathVista is a challenging dataset that integrating a variety of mathematical reasoning tasks with visual tasks. Tab. 3 compares different method performances. We also conduct experiments using GPT-3.5 and Gemini as baselines. From general visual question answering to professional math word problems, Cantor has greatly surpassed the baseline in almost all types of problems. This indicates that correct decision and modular experts can stimulate their fine-grained, in-depth visual understanding and combinatorial reasoning abilities. It is worth noting that Cantor (GPT-3.5) even surpasses GPT-4 based on CoT and PoT.



@article{gao2024cantor,
title={Cantor: Inspiring Multimodal Chain-of-Thought of MLLM},
author={Gao, Timin and Chen, Peixian and Zhang, Mengdan and Fu, Chaoyou and Shen, Yunhang and Zhang, Yan and Zhang, Shengchuan and Zheng, Xiawu and Sun, Xing and Cao, Liujuan and Ji, Rongrong},
journal={arXiv preprint arXiv:2404.16033},
year={2024}
}